
Information as an asset is still in the early adoption phase, making it a major competitive advantage for leading companies as they focus on digital transformations. In turn, data and analytics have become strategic priorities. Today, not more than 50% of organization strategies mention data and analytics as core values targeted to deliver increased value.
Many enterprises still struggle under the weight of traditional business models and analog business processes. Other business recognize their potential but cannot make the cultural shift or commit to information management.
With data collection, ‘the sooner the better’ is always the best answer.
Marissa Mayer
Here we try to enlighten on the technical know-how of utilizing company data and making it work in favor of your processes and targets. We will highlight the methods of gathering data, building an inventory of that data (data warehouse), and steps to achieve this linearly. Before diving into details first, we need to understand the terminologies and various types of data in an organization.
What is Data Warehouse (DWH)?
To make the data "Stable, Scalable, and Maintainable" from the Business analysis and Decision-making process perspective, we need to transform the raw data into a structured data model called the data warehouse (DWH). In other words, A data warehouse is a subject-oriented, integrated, time-variant, and non-volatile collection of data. The terms used for the definition of the data warehouse is described below.
Subject-Oriented: It implies that the data is organized around various subjects like product categories, items, Consumers, Customers, Professionals. Data can be further broken down to the lowest grain called Dimensions.
Integrated: It implies that the data is integrated from various sources irrespective of its format. Example - DBMS/RDBMS, Legacy systems, Cloud, Excel, Flat files.
Time-Variant: The data stored in the DWH is the trend of the overall period (excluding the real-time data), which varies depending on the timeframe selected (i.e., Month, Quarter, Year).
Non-Volatile: It implies that the data will not change w.r.t the facts captured in the form of data (read-only data). However, there may be some dimensions like Age, Address, Salary, Assets which may change over time. Nevertheless, these changes will not directly impact the specific instance/transaction when the data is captured.
A Data warehouse schema involves arranging data into two categories Measures (these data is stored in Fact tables) & Dimensions (these data is stored in Dimension tables).
Fact Tables
A Fact table typically has two types of fields/columns. Fields that contain numeric data (i.e., measurements, metrics, or facts of a business process), these fields are also called "Measures". And the other is foreign keys of dimension tables (i.e., aggregating the numeric data based on relevant dimension and granularity).
Dimension Tables
A dimension table is generally composed of one or more hierarchies that categorize the data. It is a non-numeric aspect of data using which the numeric element of data is aggregated or analyzed depending on the business rules defined. That is, these tables are generally descriptive & consist of textual values.
Why create the DWH?
- Helps organization who wants to centralize their reporting projects and get insights for decision making.
- Integrate data from multiple sources
- Merge historical data with current data (maintaining historical data)
- Improve the quality of data
- Speeding up response times to help quickly analyzing large volumes of data
- Faster and flexible reporting
This comprehensive guide covers the types of data and elements of the data warehouse that can be utilized. Now we dive into how the process building such a data model works. This will start from the raw data source to the final model having the structured data that can help us get insights into one's business. The widely used process to achieve this is the ETL (Extract, Transform & Load) method.
What is ETL (Extract, Transform and Load)?
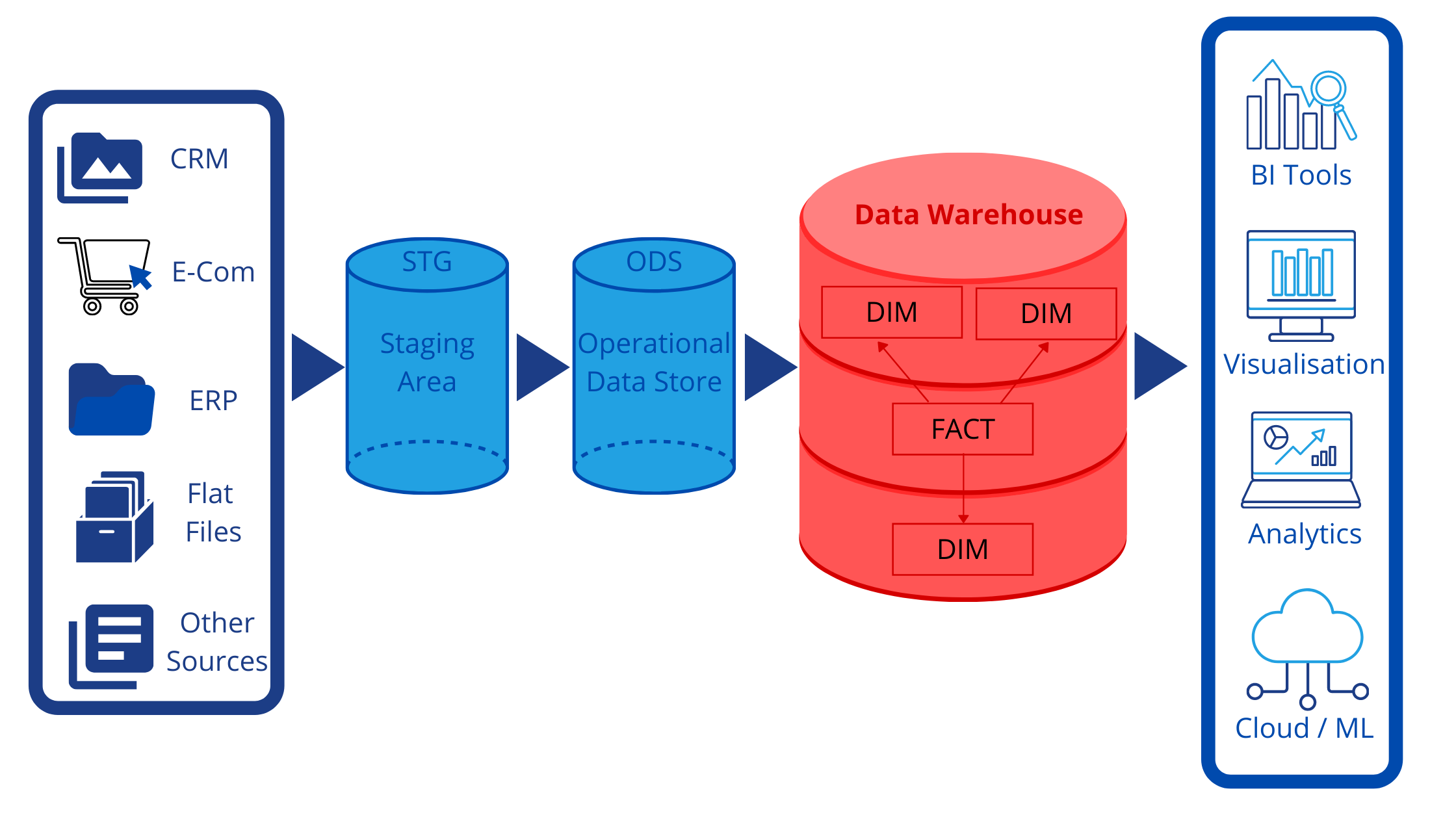
ETL is the method/process used to implement the data warehouse concept and bring it into real-world Business practice. Extracting raw data from source to the staging area (STG), transforming and maintaining the history of data in the operational data store (ODS) & finally loading data in the Dimension and Facts table in the data warehouse (EDW).
Why ETL?
In today's world, all companies have data at their disposal in one form or another. To derive meaningful business insights from that data, the concept of Data warehousing has evolved. ETL is the stepping stone for implementing the concept of data warehousing.
- Using ETL, we can pull the data from multiple sources from disparate platforms to a common platform. Thus, the companies can use the data even from their legacy systems, which they may have ignored due to technical limitations or the additional cost burden.
- ETL can handle a large volume of data and provides flexibility to integrate & re-organize data as per the business requirements.
- Like reading data from disparate systems is essential, similarly loading finished data into disparate systems for reporting and analysis is equally important. Hence ETL provides flexibility in loading data across disparate systems, thereby providing easy access to finished data for reporting, data visualization, and data science.
- Repetitive processes can be automated and hence do not require any manual intervention. Process automation helps to minimize human error, save on cost, and optimize resource utilization.
How to implement ETL?
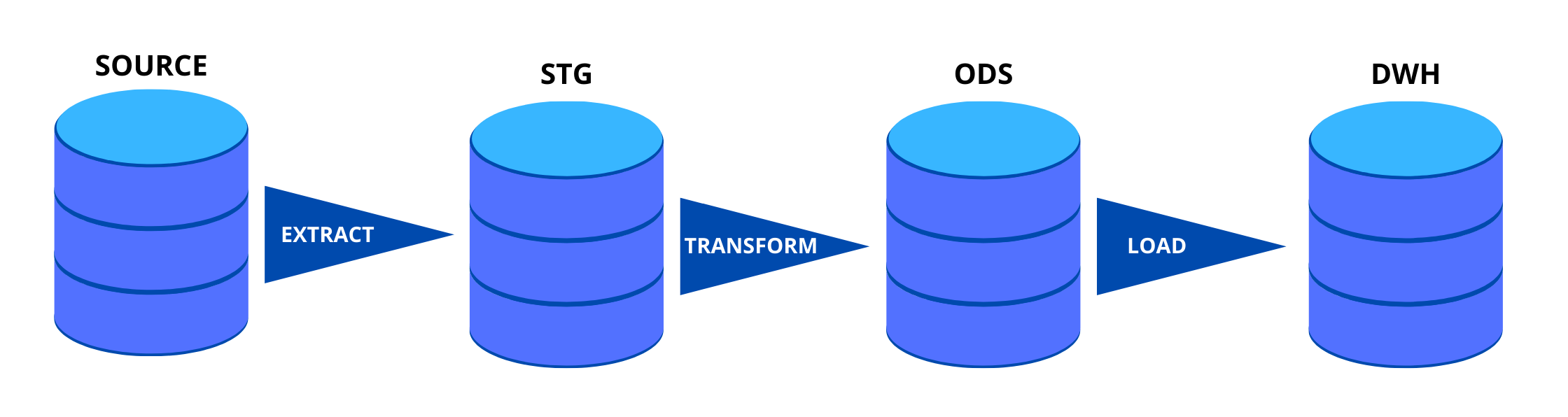
As the name suggests, The ETL process is divided into three steps.
Step – 1: STG - Extracting Raw Data to Staging Area
Extraction means fetching data from sources. Sources can be documents, spreadsheets, CSV files, Flat files, SQL Server, My SQL, Azure, Oracle, and so on. Below are a few examples.

There are two main types of extraction – full and partial.
• Full extraction is used for initial extractions or if the source having a low volume of data
• Partial extraction is used when there is no need to extract all the data or if the source having a high volume of data makes a full extract impossible. In partial extraction, only updated or new data will be extracted.
Step – 2: Operational Data Store (ODS) – Transforming data
After data is extracted to the staging, numerous potential transformations need to be performed, such as cleansing the data, resolving domain conflicts, dealing with missing elements, or parsing into standard formats, combining data from multiple sources, and deduplicating data. Transformation is generally considered to be the most important part of the ETL process. Data transformation improves data integrity and helps ensure that data arrives at its new destination fully compatible and ready to use.Maintaining a history of data, also termed as SCD (Slowly Changing Dimension), can also be implemented in ODS.
Step – 3: Loading data into Data warehouse (DWH)
The final process is loading the data into the destination (Data warehouse).There are three main types of loading data: full or initial, incremental, and refresh.
• Full or initial means a complete load of extracted and transformed data. All the staging data will be loaded into the final destination to be made ready for business users.
• Incremental load is a less comprehensive but more manageable approach. Incremental loading compares incoming data with what's already exist and only produces additional records if new and unique information is found.
• Refresh load is erasing the contents of tables and reloading with fresh data.
In general, this is how the whole process of structuring your data to be used to extract meaningful insights and assist in the growth and smooth functioning of business works. Although the steps mentioned here may vary depending on the type of data and each organization's requirements and related industry, the action plan remains the same.
Some Handy Tools for ETL
We now would like to conclude by enlightening tools to help an enterprise achieve all the aforementioned tasks. There are a plethora of custom tools available for this purpose. We will list the most intuitive, easy-to-use tools and offer the best scalability and feasibility. These few of the well-known ETL tools are listed below

Microsoft SQL Server Integration Services (SSIS) is a component of the Microsoft SQL Server database software that can perform a broad range of data migration tasks.

SAP BO Data Services (BODS) is an ETL tool used for data integration, data quality, data profiling, and data processing. It allows us to integrate, transform a trusted data-to-data warehouse system.

Informatica Power Center gives a scalable, high-performance enterprise data integration solution that supports the entire data integration lifecycle.

Talend Data Fabric offers a single suite of cloud apps for data integration and data integrity to help enterprises collect, govern, transform, and share data.
